Nodes
The Olympe platform is based on the concept of Data Flow which is somewhat similar to cells in a spreadsheet. When one cell is modified all cells that are depending on the value in that cell are automatically recalculated, which triggers more updates if other cells depend on those freshly updated cells and so on and so forth until nothing needs recalculating any more. Data flows take that concept and abstract it to be in the form of a graph of nodes instead of a grid of cells. Nodes hold a value and can have a processing function with one or more entry values. These entry values can come from other nodes.
Let's see a very simple example: Fahrenheit to Celsius conversion.
The formula is Tc = (Tf - 32) * (5 / 9)
Let's suppose we want to take the value from a text field and display the result in a label, the code would be:
label.setText(textField.getText().toONumber().minus(32).mul(olympe.df.oNumber(5).div(9)).toOString());
This, in effect creates the following data flow:
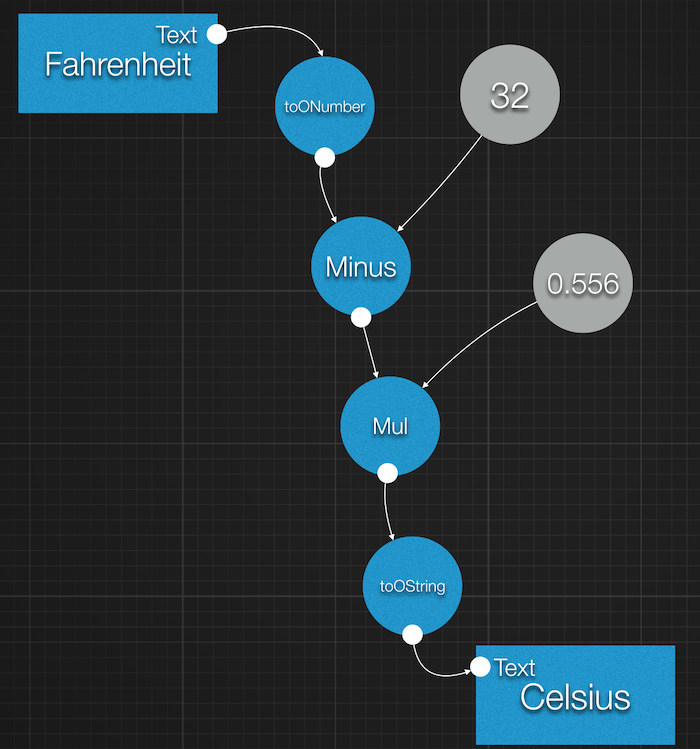
Every time the value in the text field changes the data flow is triggered, the new value calculated and automatically
displayed. No extra code was necessary.
In detail, the first node, textField.getText() provides us with an OString matching the text typed by the user.
The second node, toONumber, converts the OString into an ONumber while the third and fourth nodes a performing
the subtraction then the multiplication as per our formula.
Note that olympe.df.oNumber(5).div(9) has been computed right away since all the values are constants. That's why
it is represented into a single node with a value of 0.556. And all grey circles are not actual nodes, but constants used
by the existing nodes.
All this is possible because the Olympe platform provides replacement types for the basic javascript types:
And provides a number of utility classes like ODateTime or Vector2.
All these types are actually data flow types, meaning that their methods will actually create nodes when necessary.
It is important to understand that the output of a node can be used as the input of any number of nodes.
So, for instance, if we want to change the color of the label depending on the calculated temperature, let's say blue if it is below 10c, yellow if it is between 10c and 25c, finally red if it is above 25c. The data flow would look like this:
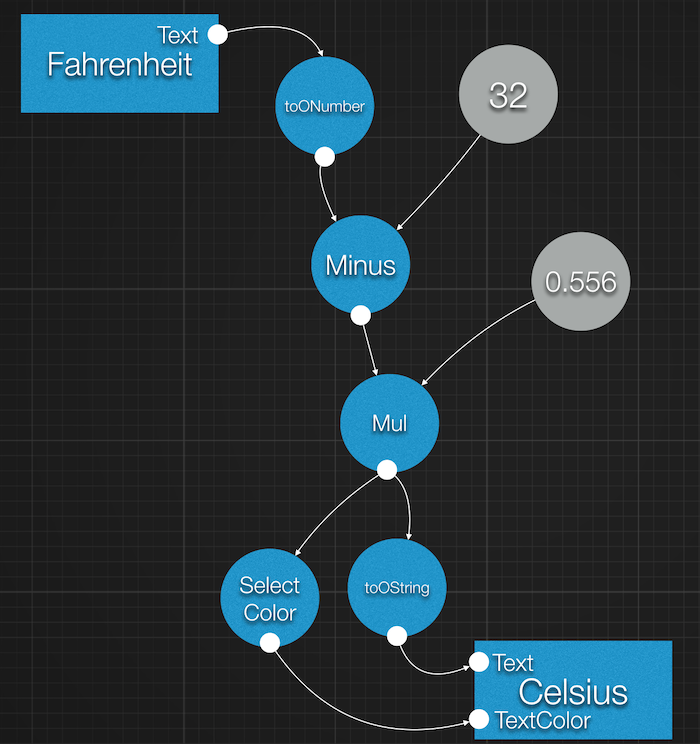
And the code would be something like:
const tempInC = textField.getText().toONumber().minus(32).mul(oNumber(5).div(9));
const color = olympe.df.transformFlows(
[tempInC],
t => {
if (t < 10) return olympe.df.Color.blue();
if (t < 25) return olympe.df.Color.yellow();
return olympe.df.Color.red();
},
olympe.df.Color
);
label.setText(tempInC.toOString());
label.setTextColor(color);
There are 3 notable things here:
- We saved our temperature calculation data flow in the
tempInCvariable so that it can be re-used. - We had to create a custom node for 'Select Color'. This is done using the
TransformFlowsfunction. We'll cover it in more details later. - In our arrow function,
tis a ONumber but it is automatically converted to a native JavascriptNumberwhen doing comparisons thanks to itsvalueOf()function.
In this example both JavaScript variables tempInC and color are holding a reference to a data-flow value. In other
words, they hold a reference to the output of a specific node. Which means that their types are the value type of their
respective nodes (ONumber for tempInC and Color for color) and that their actual value can change at any time.
In this particular case these are the nodes they are referencing.
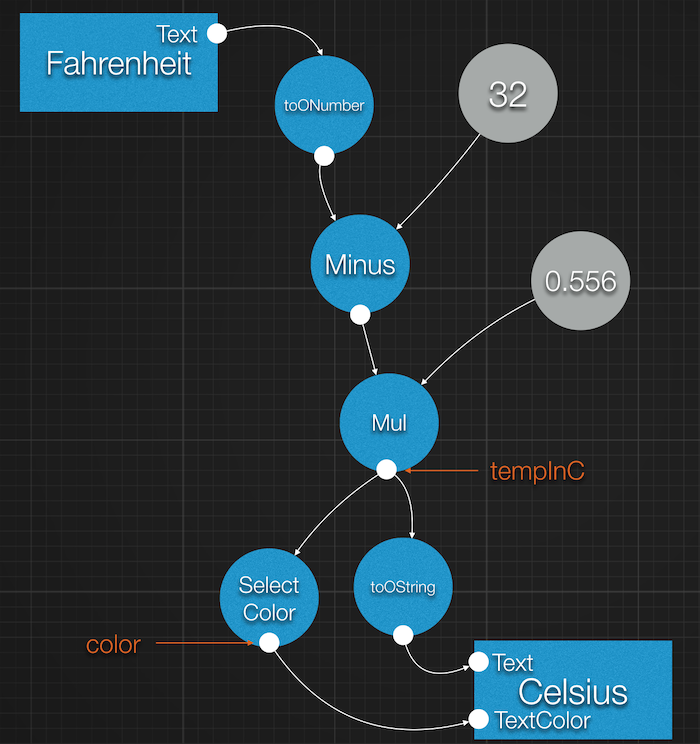
These kind of references are sometimes called 'proxies'. It is a very important point to understand when it comes to
the data flow types, like ONumber or OString, their value can change at any time and therefore they should only be
used with other data-flow types and functions.
In particular such variable may not hold a valid value. This is the case for instance when the data-flow graph, such as
the one we built for the Fahrenheit to Celsius conversion, has just been built, but the initial value (in our case the
temperature in Fahrenheit) has not been provided. At that point in time, none of the nodes of the graph have been
resolved, and they are all pending evaluation. So, both our references, tempInC and color point to something that
has no valid value. Once the user types a value in the text field, then the whole graph is evaluated and all nodes
eventually hold a valid value. When that happens, the state of the ONumber or Color variable goes from 'unresolved'
to 'resolved'. A node can and will only be evaluated when all of its inputs is 'resolved'. However, once this happens,
it will be automatically re-evaluated (and its value potentially changed) every time any of its inputs changes.
Custom Nodes
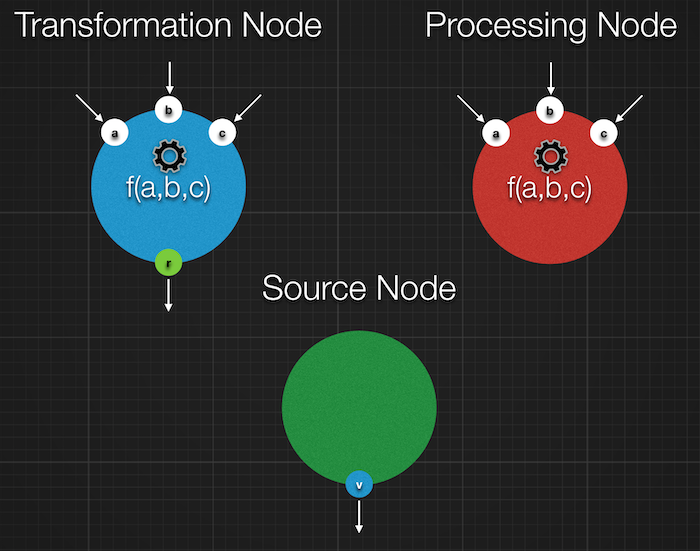
As seen in the Fahrenheit to Celsius conversion example, there quickly come cases where the developer needs to create nodes with a processing function not provided by the standard classes and methods. There are 3 kind of nodes in a data flow graph:
- Transformation nodes: Nodes that take one or multiple values in entry and generate an output value based on these
entries. This is the most common type of node. Examples of Transformation Nodes are all mathematical functions like
ONumber.plus()orONumber.div()or string manipulation functions likeOString.slice(). - Processing nodes: Nodes that take one or multiple values in entry and execute an action based on these entries but does
not provide an output value. Such a node is also called a leaf in the graph.
Label.setText()creates such a node. - Source nodes: These are nodes that have no input but provide a value, usually from an external sources like a timer,
a sensor or event manager. Examples of source nodes are
TextField.getText()whose value comes from user inputs, andgetNow()whose value (current date & time) comes from the system and is updated by a timer.
Visually these 3 kinds of node are represented like this:
Accordingly there are 3 separate functions to create custom nodes. One for each kind of node:
olympe.df.transformFlows: Creates a transformation node.olympe.df.processFlows: Creates a processing node.olympe.df.newFlowSource: Create a source node.
olympe.df.transformFlows
We've used it in a earlier example, now let's look at it in more details.
Its signature is: transformFlows(flows, transformFunction, returnType)
| parameter | type |
|---|---|
| flows | Array |
| transformFunction | function(*): T |
| returnType | function(new: T) |
| It takes an array of flows (or values), a transformation function and a return type. The transformation function | |
has to take the same number of arguments as the number of flows in the array and return an Object of type returnType. |
|
| It creates a data flow that is the result of transforming, via the specified transformation function, a set of flows. | |
| The transformation function is called every time the value of one of the flows changes and all flows have a valid value. | |
| Let's look at an example: |
const hypotenuse = olympe.df.transformFlows(
[width, height],
(w, h) => olympe.df.oNumber(Math.sqrt((w * w) + (h * h))),
olympe.df.ONumber
);
This code creates a node that calculates the hypotenuse from the width and height of a triangle. Its value is therefore of
the olympe.df.ONumber type, as specified in the 3rd parameter. And that is also the return type of the callback function
provided as the 2nd argument.
Important Note: If none of the elements in the array are flows (i.e. they are all fixed values), the execution
happens immediately and only once, in which case the results is also a fixed value.
The functions returns a data flow of type olympe.df.ONumber which can be used to feed other flows.
olympe.df.processFlows
processFlows is, to some extents, a simpler version of transformFlows since it does not require a return value and
does not return anything. As for transformFlows, the processing function will be called every time one of the provided
flows is updated, as long as all of them have a value.
Its signature is: processFlows(flows, processFunction)
| parameter | type |
|---|---|
| flows | Array |
| processFunction | function(*): void |
Example:
olympe.df.processFlows(
[a, b, c],
(a1, b1, c1) => { console.log(`Value changed for a: ${a1}, b:${b1}, c:${c1}`); }
);
olympe.df.processFutureFlows
Another particular situation is when you want something to happen only for future updates of your data flows.
Meaning you want to 'skip' the current value of the flows. Remember that all the above functions will trigger their
processing function immediately if all the flows are already resolved. processFutureFlows avoids that first trigger.
Its signature is: processFutureFlows(flows, processFunction)
| parameter | type |
|---|---|
| flows | Array |
| processFunction | function(*): void |
Example:
olympe.df.processFutureFlows(
[a, b, c],
(a1, b1, c1) => { console.log(`Value changed for a: ${a1}, b:${b1}, c:${c1}`); }
);
It is very similar to the ProcessFlows method, but it will forgo that potential first trigger.
olympe.df.newFlowSource
newFlowSource is used to create a source node. Such a node, as we've seen does not have a processing or
transformation function per se. However it has to get its value from somewhere, namely a source external to the data flows.
For instance the position of the mouse, or the current time. To that effect, newFlowSource returns an object
that implements the FlowSource interface and let you update, clear or access the value of the node.
Its signature is: newFlowSource(flowType)
| parameter | type |
|---|---|
flowType |
function(new: T) |
The FlowSource type is an interface which includes the update(val) method. This the method to call to update the
value of the source node when necessary.
Let's look at an example:
const time = olympe.df.newFlowSource(olympe.df.OString);
setInterval(
() => {
const now = olympe.df.ODateTime.now();
const s = olympe.df.oString(`${now.getHours()}:${now.getMinutes()}:${now.getSeconds()}`);
time.update(s);
},
1000);
label.setText(time.getFlow());
Here we created a node whose value is an OString and is updated every seconds with the current time. The actual
updating is done when calling source.update(s). The getFlow() method gives you access to the data-flow itself
(aka proxy);
The FlowSource interface also includes a few more methods like clear() which should be called when we want to reset that
particular node. This will set the node as 'unresolved' and will prevent all downstream nodes to be updated until
a new value is set for that source.
Snapshots
It is sometimes necessary to take a snapshot of a DataFlow, meaning to capture its value at a point in time. There are two main ways to do so:
olympe.df.getCurrentValue
This static method lets you extract the current value of any type. It works whether the object passed is a DataFlow or
any other type. If the value is a DataFlow and its node has not been resolved it will return either the provide default
value or undefined. Of course if the value passed is not a DataFlow, then it returns that value.
const val = olympe.df.getCurrentValue(flow);
if (val) {
console.log(`Current value is ${val}`);
}
olympe.df.processFlowsOnce
A more complex situation is when you want something to happen once, and only once, a number of DataFlows are resolved.
This is done by creating a special, self-destructing node using the olympe.df.processFlowsOnce method.
Its signature is: processFlowsOnce(flows, processFunction)
| parameter | type |
|---|---|
| flows | Array |
| processFunction | function(*): void |
Example:
olympe.df.processFlowsOnce(
[a, b, c],
(a1, b1, c1) => { console.log(`Values set for a: ${a1}, b:${b1}, c:${c1}`); }
);
It is very similar to the ProcessFlows method, but it guarantees that the provided processing function will be
executing only the first time all passed DataFlows are resolved, hence creating a snapshot of this values.
olympe.df.newFlowSource
You can also use a custom FlowSource to trigger such a snapshot by clearing its value immediately after setting it. Let's for instance that you want to log the value of 3 DataFlows every ten seconds. One way to achieve this is to create the following FlowSource:
const ticker = olympe.df.newFlowSource(olympe.df.OBoolean);
setInterval(
() => {
ticker.update(olympe.df.OBoolean.TRUE);
ticker.clear();
},
10000 // 10 seconds
);
olympe.df.processFlows(
[a, b, c, ticker.getFlow()],
(a1, b1, c1) => { console.log(`Values are: a=${a1}, b=${b1}, c=${c1}.`); }
);
Here we have created a ticker that will trigger every 10 seconds. Since it is cleared immediately after being set,
the node created with processFlows will not be executed even if a, b or c change their values multiple time.
In essence, we log a snapshot of a, b & c every 10 seconds (assuming all three are resolved).
Note that by making the ticker the last DataFlow in the array, it can be excluded from the arrow function parameter list.
Node LifeCycle
Nodes are being destroyed, to free memory, either explicitly by calling the destroy method, or implicitly when they
become inactive. A node is deemed inactive when these conditions are met:
- It has no parent context and no more downstream nodes. This is the normal way of destroying nodes. A node without parent means that the conditions of its creation have changed and that it should be destroyed. However, if the node still has downstream nodes it means that its value is still used and so it should be retained.
- One of its upstream nodes has been destroyed. This happens consequently to a manual destroy() call on the upstream node. It means that one of the inputs for this node will no longer provide any value, therefore the inner function will never be called again and as a consequence, the output value will never change.
As seen here, the parent context is an important concept since the life cycle depends on it. By default, the parent of
a node is the Root context, however when nodes are created during the execution of the processing function of another node,
then that node (sometimes called the current executing node, or context node) becomes the parent of all the created
nodes. Subsequently, when the processing function is executed again, then all previously created nodes are orphaned, meaning
their parent context is set to none making them candidates for garbage collection (see above conditions).
In the general case, this is managed transparently by the platform. However there quickly come situations where we need
to manage the life cycle of nodes more directly. This is the case for instance when nodes are created in a callback that
will be invoked from a completely different context. If we don't want these nodes to be tied to the lifecycle of that,
sometimes unknown, context, then we need to specify where they belong.
Let's take an example: We want to create flows only when one particular set of other flows will be all resolved for the
first time. We will use the olympe.df.processFlowsOnce() function mentioned earlier. However, if we don't do anything
special then these nodes will be attached to the node created by processFlowsOnce which will be immediately destroyed
after performing the function (hence the 'Once'). What we really want is to attach them the parent context of that one.
How can we do that?
This is where the ExecutionContext interface comes in:
const context = olympe.df.getCurrentContext();
olympe.df.processFlowsOnce(
[a, b],
(_a, _b) => {
context.run(() => {
// ... I can safely create nodes!
});
}
);
The first line captures the current context by calling olympe.df.getCurrentContext() which returns the ExecutionContext
under which the code is running at that particular moment. Inside the callback, we use context.run() to make sure the
code is executed in the same context instead of the one created by processFlowsOnce().
Other useful functions dealing with contexts are:
olympe.df.getGlobalContext()which returns therootormaincontext. The global context can never be destroyed and its life-span is the one of the application. You should be mindful of what you create within that context as it might never be garbage collected automatically.olympe.df.setCurrentContext(context)which sets the current executing context to the specified one and returns the previous one.new olympe.df.SimpleContext()Let you create an empty context, which will be attached to the current one, so you can control its lifecycle directly.context.destroy()Let you explicitly destroy a context. This will render all its children orphans and they will become candidates for destruction if their value is not used.context.detachAll()Let you detach all the children of this context, rendering them orphan without destroying this context. Nodes with a processing function will call this method every time they need to re-execute it (i.e. when one of their input values has changed).context.onDestroy()Let you register a callback to be executed when that context is destroyed. Which might be useful when some extra cleaning is necessary for example.context.onDetachAll()Let you register a callback to be executed when that context will detach all its children (happens for instance when a node has to run its processing function again).